猿人学第一题-JS混淆-源码乱码
我们在爆破用户名密码的时候,用户名经常加密,加密混淆js情况也会存在,发现猿人学这个网站可以很好的学习JS对抗,感谢作者出了这么优秀的题目,我们现在看一下第一道题。
做题步骤
首先我们拿到题目,发现为抓取数据求平均值。

我们使用burp抓个包看一下
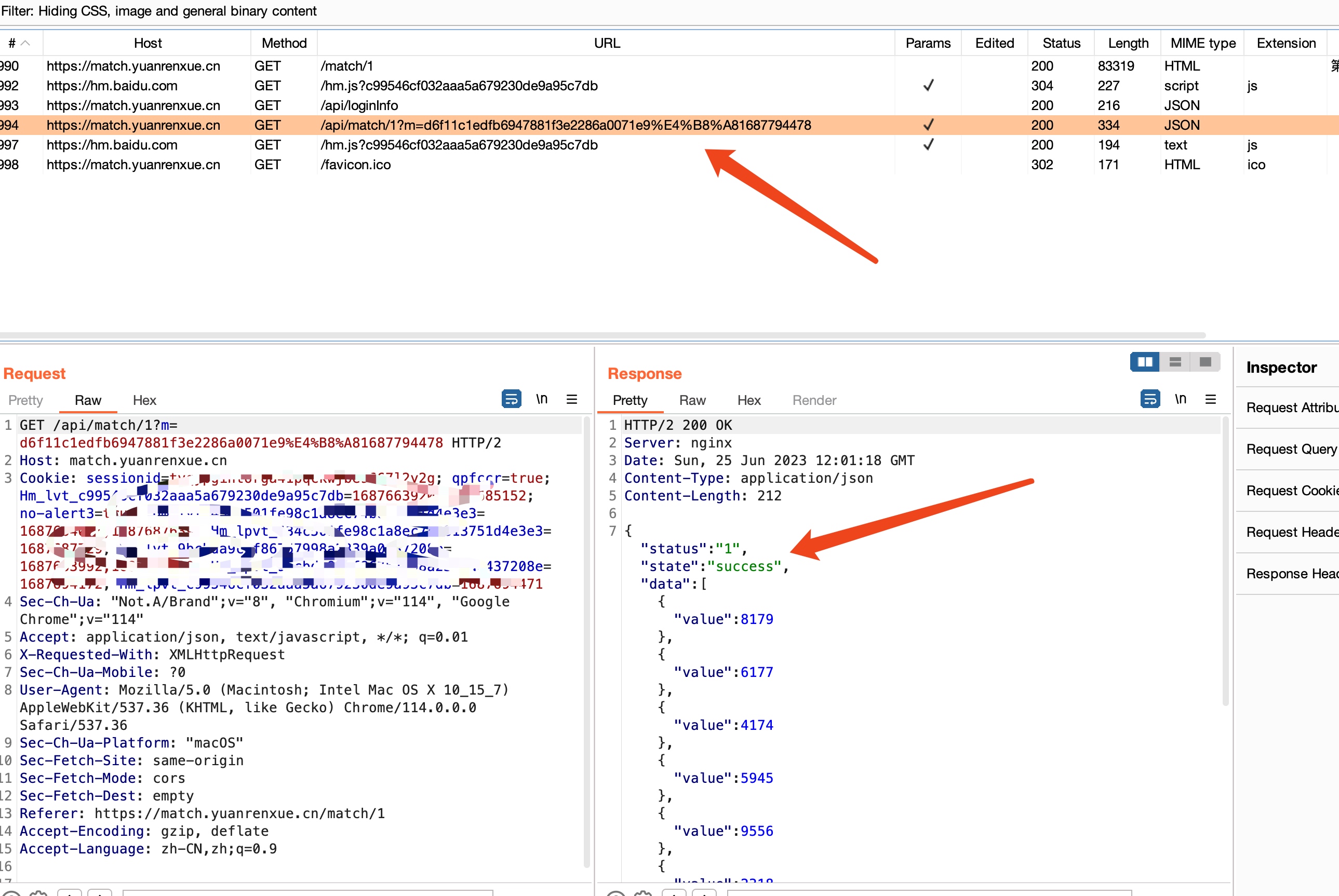
我们发现他的这个请求数据里面存在机票的价格。
接着我们切换到第二页,我们发现多了一个page参数,它用来控制页数。

我们还发现m参数的值是不断变化的,那么他应该是某个js动态的去生成的,我们去浏览器里面调试跟踪看看。
我们按F12,进入开发者模式,会强制进行的debug。
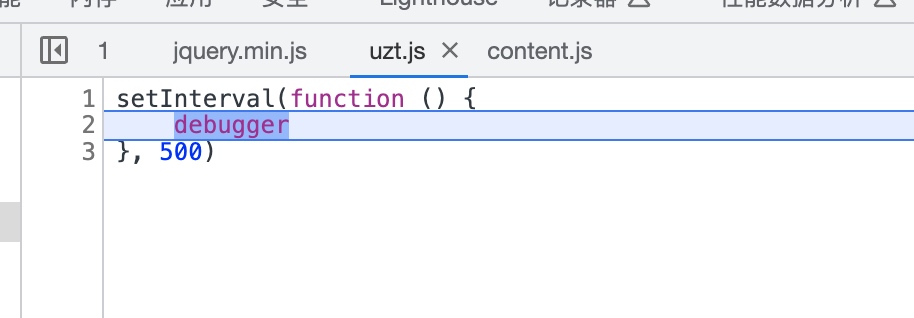
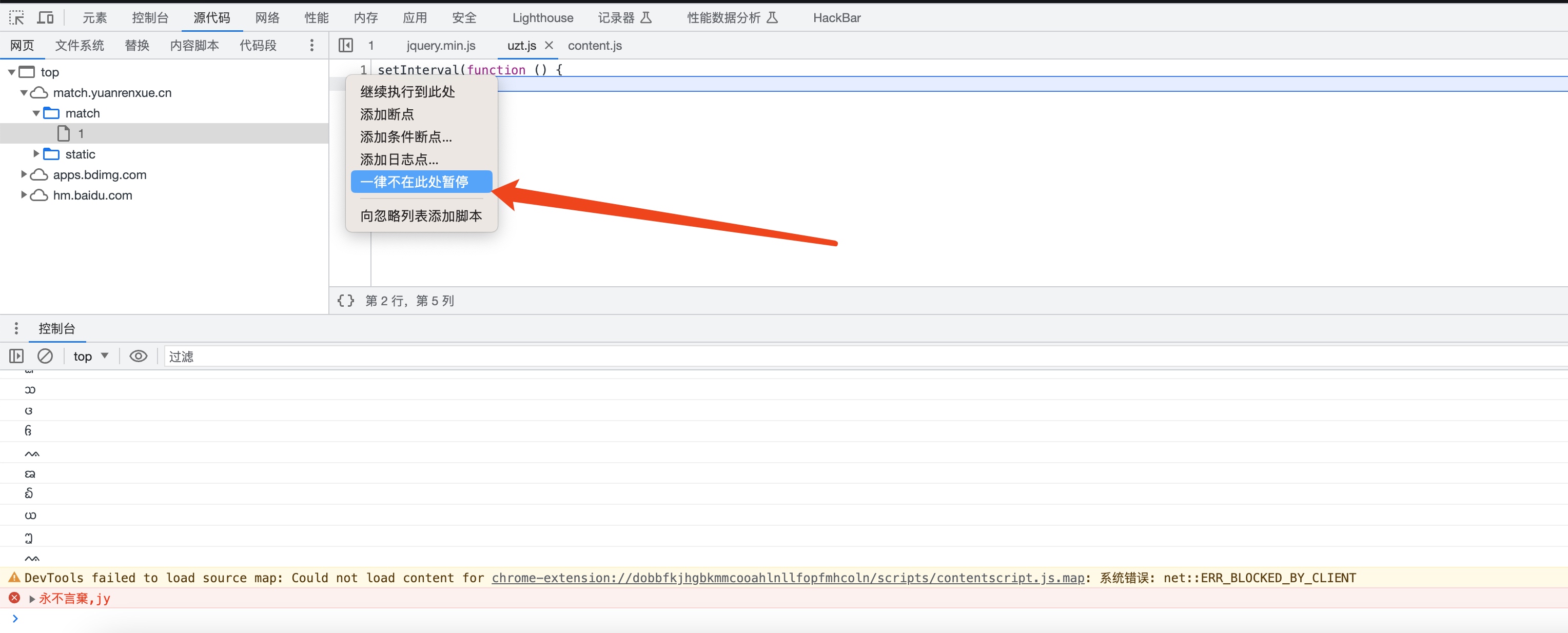
我们将debug取消掉就可以正常的调试了。
这里我们有两种方式找到调用堆栈。
在网络里面可以看到调用堆栈。

可以点击调用堆栈中的js,去分析源码。
XHR断点
xhr:XMLHttpRequest在后台与服务器交换数据,这意味着可以在不加载整个网页的情况下,对网页某部分的内容进行更新。
因为请求是xhr类型的,所以我们可以使用XHR断点进行调试。
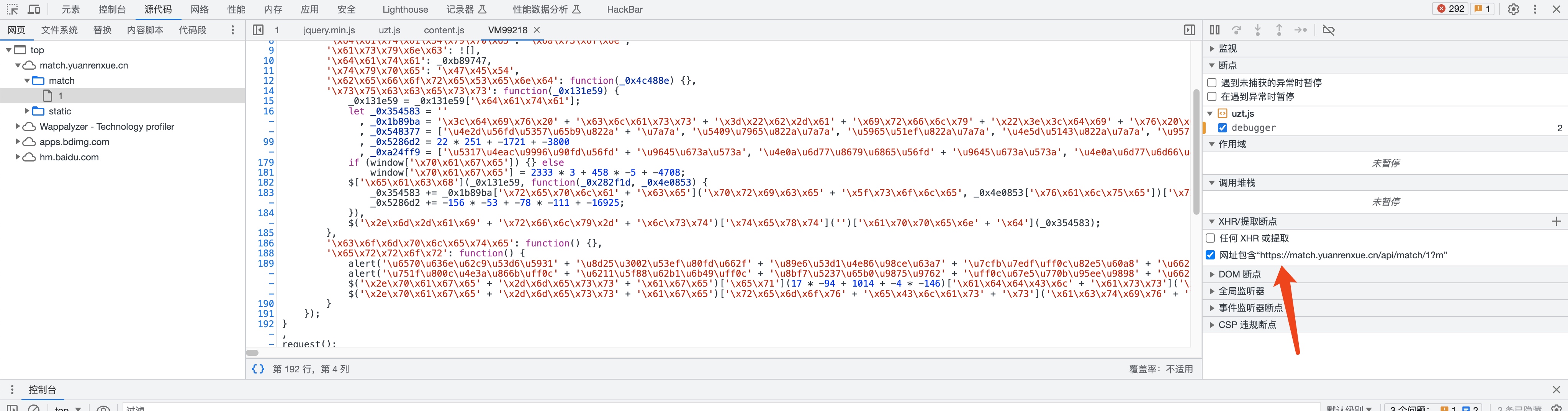
然后我们重新获取一下网站的数据。
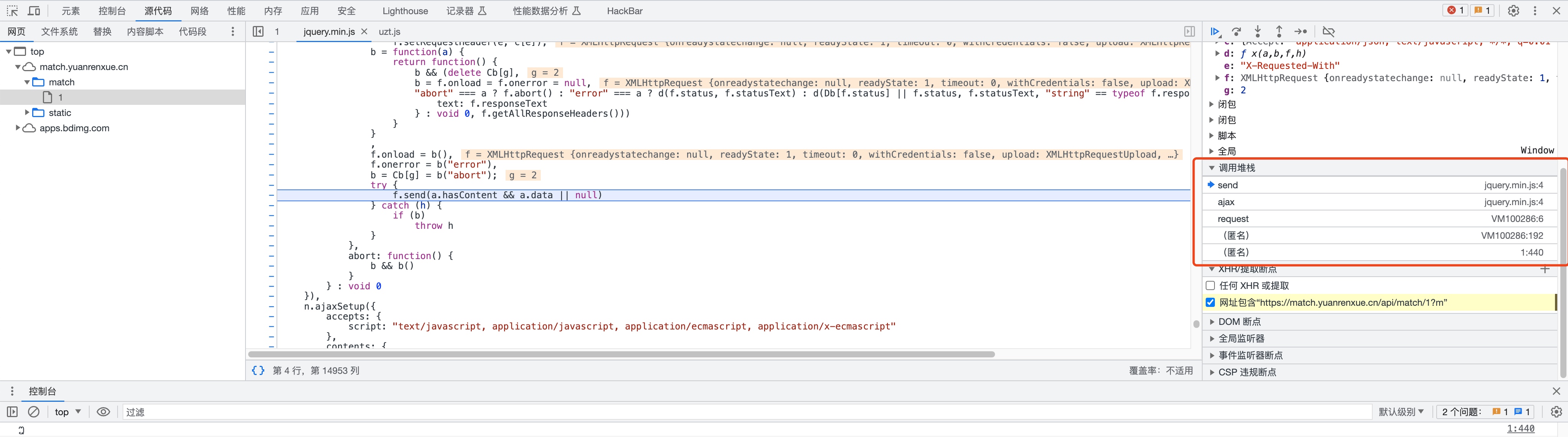
我们看到有这几个调用堆栈。逐个去分析代码会发现m的关键生成位置在这个地方。
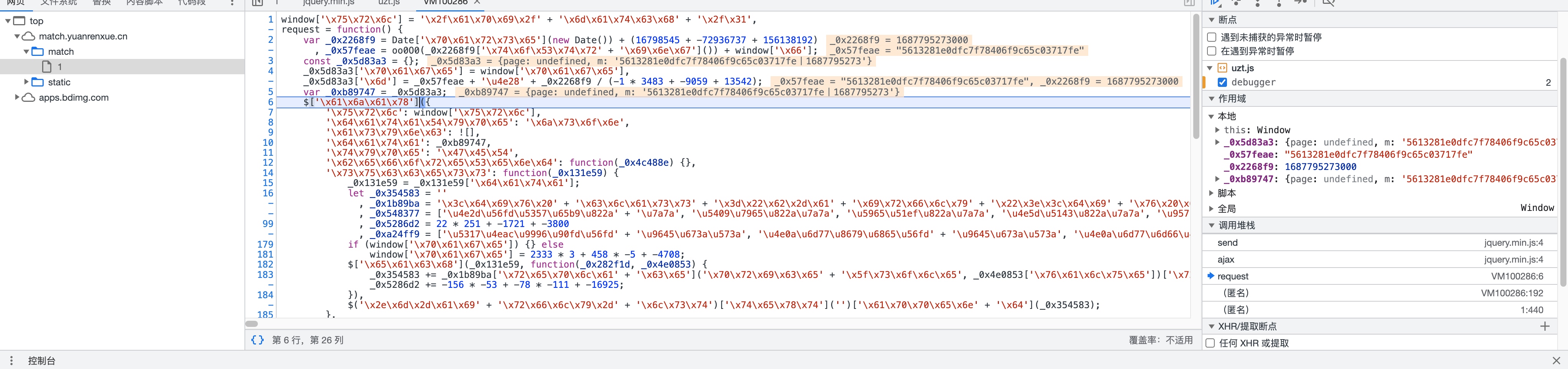
代码被混淆了,对与这种0x的混淆,还是比较好还原的。可以使用下面的网站进行还原
1
| https://tool.lu/js/index.html
|
还原后得到关键代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| (window["url"] =
"/api/" + "match" + "/1"),
(request = function () {
var _0x2268f9 =
Date["parse"](new Date()) +
(16798545 + -72936737 + 156138192),
_0x57feae =
oo0O0(_0x2268f9["toStr" + "ing"]()) +
window["f"];
const _0x5d83a3 = {};
(_0x5d83a3["page"] = window["page"]),
(_0x5d83a3["m"] =
_0x57feae + "丨" + _0x2268f9 / (-1 * 3483 + -9059 + 13542));
var _0xb89747 = _0x5d83a3;
|
虽然还有混淆,但是已经不妨碍我们读懂逻辑了。
m的生成过程为:
1
| _0x5d83a3["m"] =_0x57feae + "丨" + _0x2268f9 / (-1 * 3483 + -9059 + 13542);
|
也就是
1
| _0x5d83a3["m"] =(oo0O0((Date["parse"](new Date()) + (16798545 + -72936737 + 156138192))["toStr" + "ing"]()) + window["f"]) + "丨" + (Date["parse"](new Date()) +(16798545 + -72936737 + 156138192)) / (-1 * 3483 + -9059 + 13542)
|
在以上关键代码中,我们有些是不认识的,我们使用console.log去查看哪些是局部的哪些是全局的。
我们在控制台执行
1
| (oo0O0((Date["parse"](new Date()) + (16798545 + -72936737 + 156138192))["toStr" + "ing"]()) + window["f"]) + "丨" + (Date["parse"](new Date()) +(16798545 + -72936737 + 156138192)) / (-1 * 3483 + -9059 + 13542)
|
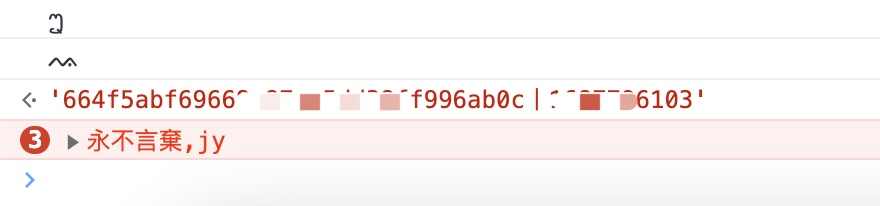
发现全是全局的,那么我们就可以直接使用python的selenium去执行了。
完整代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| import json
import time
import urllib
import requests
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--ignore-certificate-errors")
chrome_options.add_argument("--proxy-server=http://127.0.0.1:8080")
driver = webdriver.Chrome()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://match.yuanrenxue.cn/match/1')
price=[]
def getdate(i,m):
global price
url="https://match.yuanrenxue.cn/api/match/1?page={i}&m={m}".format(i=i,m=m)
headers = {"user-agent": "yuanrenxue.project"}
req=requests.get(url,headers=headers)
print(req.text)
data = json.loads(req.text)
values = [item['value'] for item in data['data']]
price=price+values
for i in range (1,6):
exec="""var m = (oo0O0((Date["parse"](new Date()) + (16798545 + -72936737 + 156138192))["toStr" + "ing"]()) + window["f"]) + "丨" + (Date["parse"](new Date()) +(16798545 + -72936737 + 156138192)) / (-1 * 3483 + -9059 + 13542);
return m"""
result = driver.execute_script(exec)
result= urllib.parse.quote(result)
getdate(i,result)
time.sleep(2)
average = sum(price) / len(price)
print(average)
driver.quit()
|
tips
- 调用网站的js去获取变量值,肯定不如直接将关键js抠出来去执行效率高,这个后续去做。
- 虽然这些训练都是针对爬虫的训练,但是网站安全中的这些js对抗都是差不多。比如用户名密码加密这些操作。